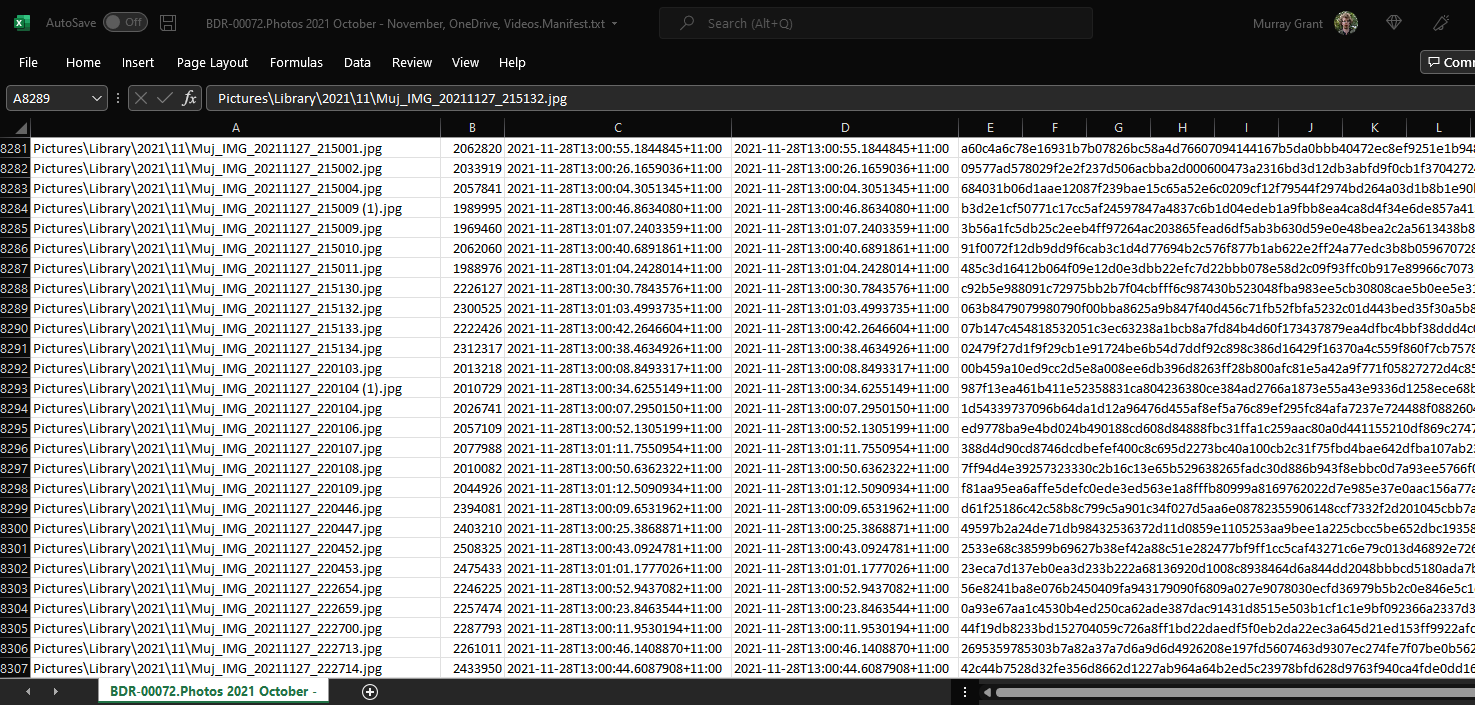
So many choices for backups! You can read the full series of Long Term Archiving posts which discusses the strategy for personal and church data archival for between 45 and 100 years.
Background
So far, we have considered the problem and overall strategy, possible failure modes, how we will capture the required data, and likely access patterns of the backups.
Now we’re up to the fun part!Time to research the options available to do backups and consider how well they meet our criteria.
Goal
List common backup platforms or technologies, and evaluate them based on the criteria we’ve identified over the last few posts.
Remember, I’m planning to backup personal data and church data (not-for-profit organisation).These evaluations mostly apply to a small business (20 or less employees), but less so for medium or large organisations - they will be processing orders of magnitude more data.
- Cost - capital, ongoing, price per unit storage.
- Reliability - how frequently should we expect failures.
- Longevity - how long should we expect the backup to survive.
- Access - how easy & fast is it to access data.
- Scale - how large can you grow your data.
- Simplicity - what technical skill is required.
- Automated - to what degree can you automate.
- Security - how secure is your data.
- Recommendations - what is the technology most suited to.
Disclaimer: Some of the criteria are pretty arbitrary and subjective. Others will be based on other studies or maths.As always, do your own evaluations to determine if any service or technology is suitable for you.
Cloud

The Cloud is a fantastic place for backups and archives.It enables individuals and small businesses to access the same scale of storage as multi-national corporations.
Remember, the cloud is a euphemism for “renting someone else’s computer”.It is relatively cheap and highly reliable - essentially, the cloud provider takes responsibility for all the boring aspects of storing data.But in accessing those features, you give up ultimate control of your data.
So this advice applies to all cloud based backups: have an off-line copy as well.
Cloud: Object Storage

AWS S3 popularised “cloud storage”.It works by storing key-value pairs: some kind of name, and a blob of data.It has conventions for creating a filesystem-like view.And adds permissions, storage tiers, and various other features.You can “put” data into a “bucket”, and then retrieve it later by its name.
Alternatives: Azure Blob Storage, Backblaze B2.
Capital Cost: $0
Ongoing Cost / GB / Year (AUD): 30c (AWS), 25c (Azure), 6c (Backblaze). Plus network costs, API usage, and who knows what else.
Calculating costs of cloud storage is incredibly difficult; there are any number of pricing tiers, levels of redundancy and additional costs beyond raw data storage (eg: network uploads / downloads, API usage).The cloud promised “only pay for what you use”, but delivered “our pricing model is so complex, until you actually use our service, you have no idea what it will cost”.You should use the “pricing calculators” provided by each cloud service to get a rough estimate of cost.
Cost to Store 1TB for 1 year (AUD): ~$310 (AWS) (plus network / API / etc)
Reliability: All cloud providers use redundant storage within individual servers, data centres and can even replicate data between different geographical regions. While there are occasional outages due to network issues, your raw data is incredibly safe.Even if there are internal errors or failures (and there will be), the provider has automated systems to detect and correct them.
Effectively, you can safely assume you will never see a failure when using the cloud.This is by far the biggest advantage of the cloud: it is really expensive to achieve similar reliability by rolling your own.
Longevity: All cloud providers have long term archive options (eg: S3 Glacier, Azure Archive), and the same principals behind their high reliability mean your data is safe over 10+ years.So long as the provider itself remains in business, it is safe to assume your data is available.
Access: Is generally limited by your own Internet connection - as with any cloud solution, if your Internet connection is poor, the cloud will perform badly.S3 is the industry standard protocol for cloud object storage, and there are many apps available to upload / download / browse your data.Many backup solutions have built in support for S3 storage.
Scale: Object storage allows for Petabyte level storage (1 PB is 1 million GB).For personal usage, small or medium business, you can assume there are no technical limits.The first thing that will break is your credit card!
Simplicity: Any nerd or technically minded individual will have little trouble using object storage.However, cloud providers pitch this technology at technical people; your mom-or-pop is going to struggle signing up for these cloud providers, let along configuring their devices.
Automated: Cloud providers are available 24/7, and were primarily designed to be accessed by machines rather than humans.Their support for automation is excellent.Low level APIs are available (if you’re a programmer), graphic clients are available (for interactive access), command line clients are available (for automation via scripts).
Security: It is a vested interest of cloud providers to ensure privacy of your data, and security via access permissions & user authentication.Having said that, most cloud providers can peek at your data if they choose (although have strict policies prohibiting that) - you should configure any backup software to encrypt your data.And it is common for permissions to be accidentally set to “public” and allow anyone to download your data.
Recommendations: Object storage is an excellent candidate for backups and long term archiving.The only caveats are, 1) you need a nerd to get started, and 2) you have to trust they won’t go out of business in the next 50 years.
| Criteria | Rating |
|---|
| Capital Costs | 5/5 |
| Ongoing Costs | 3/5 |
| Reliability | 5/5 |
| Longevity | 4/5 |
| Access | 5/5 |
| Scale | 5/5 |
| Simplicity | 3/5 |
| Automation | 5/5 |
| Security | 4/5 |
| Overall Suitability for Backups | 5/5 |
| Overall Suitability for Archives | 3/5 |
Cloud: Sync Service

DropBox is the original cloud sync service.With similar services provided by OneDrive, Google Drive, Sync.com and others.
It is by far the simplest way of backing up data from your devices.You keep your files in designated folders, and the synchronisation service magically copies files to the cloud.When another device makes changes, they are magically copied to your device.Indeed, its so simple that “backups” in Windows 10 are “keep your files on OneDrive” - all the older backup features like File History or Backup and Restore are second class citizens.
Most cloud sync providers are able to see the contents of your data.Several providers make a point of confidentiality, by encrypting data on your computer before it is uploaded (zero knowledge cloud storage).This may be a desirable characteristic when making backups.Providers include: pCloud, Tresorit, and SpiderOak
Capital Cost: $0
Ongoing Cost / Year (AUD): $150-$200 for at least 1TB of storage.
- Dropbox ~$190 for 2TB
- Google Drive ~$150 for 1TB
- OneDrive ~$130 for 6TB (6 users * 1TB)
- Sync.com ~$140 for 2TB
- pCloud ~$140 for 2TB
- Tresorit ~$180 for 500GB
- SpiderOak ~$200 for 2TB
Pricing above is for personal accounts; most services offer a business or professional level account which is more expensive and has more business orientated features.At the end of the day, if you want to backup data, it doesn’t matter; personal, professional or business is all the same.If you want to share files with other people, the professional accounts may be of interest.
Reliability: All cloud providers use redundant storage within individual servers, data centres and can even replicate data between data centres. While there are occasional outages due to network issues, your actually data is incredibly safe.Even if there are internal errors or failures, the provider has automated systems to detect and correct these.
Effectively, you can safely assume you will never see a failure when using the cloud.This is by far the biggest advantage of the cloud: it is really expensive to achieve similar reliability by rolling your own.
Longevity: So long as the provider itself remains in business, it is safe to assume your data is available.Note that these consumer orientated cloud services don’t have the same guarantees about long term storage - that is, AWS S3 offers tiers specifically for retaining data for 10+ years for compliance purposes; none of the consumer services make such claims.
Access: Is generally limited by your own Internet connection - as with any cloud solution, if your Internet connection is poor, the cloud will perform badly.All these services have an app you need to install for the best connectivity, most (all?) offer a web interface as well.Most apps support iOS, Android, Windows, and MacOS. Linux is more hit and miss.
Scale: Most consumer cloud storage tops out around 5TB.Google Drive offers up to 30TB.If you want more storage, you’ll need to sign up for another account.This level of scale is fine for documents or photos, but if you’re recording 4k video you will hit the 5TB limit pretty quickly.
Simplicity: These services are aimed at every-day users.They are usable by pretty much anyone.
Automated: Cloud providers are available 24/7.But these consumer services are designed for humans rather than computers.At least, you will need to have a device with a person logged into it (so they won’t work on headless services).Having said that, there is software available which allow automation via scripts.
Security: It is a vested interest of cloud providers to ensure privacy of your data, and security via access permissions & user authentication.Most cloud providers can peek at your data if they choose (although have strict policies prohibiting that).It is difficult to encrypt data when using cloud sync apps.Fortunately, access permissions are private by default.
Recommendations: Cloud Sync based storage is a very good candidate for backups, particularly for everyday users.But not as good for long term archiving.And, as with any cloud provider, you need to trust they won’t go out of business.
| Criteria | Rating |
|---|
| Capital Costs | 5/5 |
| Ongoing Costs | 4/5 |
| Reliability | 5/5 |
| Longevity | 3/5 |
| Access | 5/5 |
| Scale | 4/5 |
| Simplicity | 5/5 |
| Automation | 4/5 |
| Security | 4/5 |
| Overall Suitability for Backups | 5/5 |
| Overall Suitability for Archives | 3/5 |
Hybrid
Hybrid systems allow many of the advantages of cloud storage, but you host the service on your own servers.Essentially, a cloud-like system, but using your own disks and hardware for storage.
If there is data that you can’t store in the public cloud (perhaps its too sensitive or you are prohibited by law) but still want a cloud-like interface to access it, then hybrid is the way to go.You retain ultimate control over your data, but need to take responsibility for maintaining the systems hosting said data.
Hybrid: Cloud Like

There are a number of Cloud Sync services that can be self-hosted.
OwnCloud / NextCloud are very similar services that behave like DropBox.SyncThing / Resilio are more like a writable version of BitTorrent.
All can be used as a backup, as long as you provide your own hardware.
Capital Cost (AUD): All need a server of some kind. Some need more powerful servers than others.
- All the above services can function on a Raspberry Pi, which puts the entry cost at ~$400 including a disk.But this provides no redundancy if your disk fails.
- See below for NAS devices, which are the cheapest devices available with redundant disks, starting from ~$600.
- An desktop can be a functional server (even if the quality of parts might not be as high), starting from ~$1000.
- A computer with “server” written on it will cost at least $2000.
Ongoing Cost / Year (AUD):
All services listed have free options, although that may be limited for personal use only.Most have business / enterprise pricing per user per month. You’re looking at $400 - $1000 per year for 5 users, depending on the service.
Fortunately, because these companies are selling you a product, their pricing is much easier to understand than AWS S3 or Azure Blob Storage!
Reliability: Because these are self-hosted, their reliability depends on the hardware you purchase and Internet connection available.The entry level costs (above) are NOT going to give you high reliability; cheapest is not best if you want reliability.Purchasing 3 of everything is a great way to improve reliability!But that means your capital costs just tripled.I’ll discuss reliability of hard disks in a NAS below in more detail.
SyncThing and Resilio are designed to scale out as you add more devices; OwnCloud and NextCloud not so much.
If you’re only using these devices at home or at business, your LAN may be plenty reliable for your needs.But, I’m assuming the “hybrid” part means you will want to access data or devices remotely, so a reliable Internet connection is important.
In Sydney Australia, I’ve found personal Internet via Internode more than reliable enough to host my own website.However, this may not be true in all part of the world (or even all parts of Sydney)!
Longevity: Again, I’ll discuss how long you can expect your hard disks to last for below.Your server(s) will last as long as you maintain / replace them on failure.
Access: These services require their own apps to run, which generally makes them easy to use.Otherwise, access to data is similar to other cloud sync providers.But with one important difference: you can always connect to the server directly if you need the data and the app isn’t working right.
Scale: I’m not aware of inbuilt limits for these services.OwnCloud / NextCloud will scale up to the size of your server.SyncThing / Resilio are distributed, so you can store more and more data as you add more and more servers.
Simplicity: “Self-hosted” means you need at least a computer nerd to get you started, possibly an IT professional.These services are moderately difficult to install, and pretty easy to use, but are certainly not aimed at mom-and-pop users.
Automated: All services can be automated within their own apps - generally this assumes a human logged onto a computer.Outside their apps, there is good scope for scripting and automation - “self-hosted” allows a high degree of flexibility in this department, if you have the expertise available.
Security: Data is in your own hands, so the security and privacy of your hybrid solutions are equally in your hands.All software listed have built in security and encryption - so the main point of failure is human: incorrect configuration or simply forgetting to revoke access to ex-employees.Also, make sure you keep software up to date - bugs and security vulnerabilities are found frequently, updates are key.
Recommendations: Hybrid Cloud Sync storage is a good candidate for backups and long term archiving (because you control the underlying hardware).Even if the parent company goes out of business, you’ll have whatever you last installed.Perhaps their best use case is to bridge between the public cloud and your own servers; which makes them a really good fit in the business world.
| Criteria | Rating |
|---|
| Capital Costs | 3/5 |
| Ongoing Costs | 4/5 |
| Reliability | 4/5 |
| Longevity | 4/5 |
| Access | 4/5 |
| Scale | 4/5 |
| Simplicity | 2/5 |
| Automation | 4/5 |
| Security | 4/5 |
| Overall Suitability for Backups | 4/5 |
| Overall Suitability for Archives | 3/5 |
Hybrid: Distributed Object Store

There are a number of “S3 compatible” services available, the two most popular are MinIO and Cyph, but there are plenty of others out there.Because they are “S3 compatible”, anything that can backup to AWS S3 can be configured to backup to these services.They need to be self-hosted.
Although not S3 compatible, the Interplanetory File System is a promising distributed system, which can use public providers, or self-hosted servers.The big feature of IPFS is “immutable content based addressing”, which is a fancy way of saying “you can’t every change something you upload on IPFS”.When archiving data for 45+ years, that is a very good property.On the other hand, it is relatively new and somewhat experimental.And the big gotcha is: everything is public on IPFS, which is a very bad property when keeping sensitive or confidential data - encryption is a must.
Capital Cost (AUD): All need a server of some kind. See above for starting costs.
Ongoing Cost / Year (AUD):
All services listed have free (open source) options.MinIO has commercial licensing options.
Generally, your ongoing costs are going to be related to the hardware more than software.As these are distributed solutions, they work best on many servers.At some point, if you install enough servers, you’ll have a data centre like AWS and Azure operate!
IPFS has a public cloud that let’s you “pin” content on other servers - the rough equivalent of uploading your data.Costs range ~$1-2 per GB per year (significantly higher than AWS / Azure).
Reliability: Because these are self-hosted, their reliability depends on the hardware you purchase and Internet connection available.The entry level costs (above) are NOT going to give you high reliability; cheapest is not best if you want reliability.I’ll discuss reliability of hard disks in a NAS below in more detail.
All these services are distributed and designed to scale out as you add more devices.And distributed systems mean you should probably have 5 or 7 of everything (or more).
Longevity: Again, I’ll discuss how long you can expect your hard disks to last for below.Your server(s) will last as long as you maintain / replace them on failure.
Access: MinIO and Ceph are S3 compatible, so its no harder than AWS to access data.IPFS runs its own service and provides command line, web based and virtual file system access.Because they are distributed services, the raw data on disk is not easy to read - data is split and copied between servers automatically.So direct access to servers is less useful.
Scale: I’m not aware of inbuilt limits for these services; because they are distributed, they are designed to scale up as you add more servers.MinIO and Ceph are designed for 10TB and up.IPFS is designed for effectively unlimited storage (though its relative immaturity means that hasn’t been extensively tested).
Simplicity: These services are even harder to use than “bring your own server, install this service, off you go”.Public IPFS is close to that level (if a bit experimental).MinIO and Cyph are designed to be integrated as part of other server infrastructure.It is possible to create your own private IPFS network, but that is quite technical.However, once your IT department looks after all the technical stuff, scripted backups should be nice and simple.
Automated: As with the “real” AWS S3, these services have excellent APIs and support for automation.MinIO and Cyph should work with any S3 compatible backup software.IPFS has command line scripting support.
Security: Data is in your own hands, so the security and privacy of your hybrid solutions are equally in your hands.All software listed have built in security and encryption - so the main point of failure is human: incorrect configuration or simply forgetting to revoke access to ex-employees.Also, make sure you keep software up to date - bugs and security vulnerabilities are found frequently, updates are key.
Recommendations: Creating your own S3 Compatible object store is the ultimate hybrid cloud - having all the features of S3 but on servers you control.This is the kind of setup that medium or large business may find attractive, but it’s going to be out of reach of individuals and small business.
IPFS feels like it could be a fantastic solution for long term archiving.But its quite complex and expensive compared to other options.
| Criteria | Rating |
|---|
| Capital Costs | 3/5 |
| Ongoing Costs | 4/5 |
| Reliability | 5/5 |
| Longevity | 5/5 |
| Access | 4/5 |
| Scale | 5/5 |
| Simplicity | 1/5 |
| Automation | 4/5 |
| Security | 4/5 |
| Overall Suitability for Backups | 4/5 |
| Overall Suitability for Archives | 4/5 |
On-Premises
The traditional way to do backups and archives is to do it yourself.
Unlike the cloud, we can’t take advantage of economies of scale, nor the ultra high reliability.But we do retain ultimate control of our data - there is no external 3rd party who can cut us off from our precious data.No account that might be hacked, or locked.And no cloud provider that might go out of business.
We have ultimate control and ultimate responsibility with on-prem backups.
On-Prem: NAS (online disks)

Pretty much everything in IT runs on servers with disks.
Whether its the largest cloud provider or a tiny website, the service you access needs to run on real hardware.There might be many layers of virtual machines and services between the website and the hardware, but make no mistake, everything runs on servers with disks eventually.
For backups, we’re interested in many cheap disks.And the simplest way to achieve that is Network Attached Storage.
A NAS device is a small server that optimises for lots of disks (as opposed to CPU power).The ones we’re interested in have multiple disks, to allow redundant storage.So if one disk fails, your data remains intact.
Key players include Synology, QNAP, and TrueNAS.TrueNAS is the one I use because it uses ZFS for storage, but it’s more expensive than other brands.I don’t have direct experience with Synology or QNAP.
Capital Cost (AUD):
The cheapest NAS supporting 2 disks start around $400. And 4 disk models from $500.
You need to add disks for the NAS to be useful. 1TB disks are ~$100ea. 4TB looks to be the best value for money at ~$160ea. 8TB jumps to ~$350ea.
So, a basic NAS with 2 x 1TB will cost ~$600. A decent NAS with 4 x 4TB disks is ~$1200. Or a high end model with 8 x 8TB disks is ~$5000.
The TrueNAS software is available for free, but you need to supply your own hardware.My estimate is $1500-$2000 if you want to DIY with quality parts and 2 x 4TB disks.Genuine TrueNAS hardware starts in a similar range (and Australian buyers pay a premium for shipping, unfortunately).
The estimated life time of your NAS is 5-10 years.
Ongoing Cost / Year (AUD): Once you have purchased your NAS there are two main ongoing costs: electricity and network access. And don’t forget to add a maintenance allowance.
My electricity costs ~21c / kWH in Sydney.Your NAS will be running 24/7, and will consume 60-120W (depending on size).My math for this works out to an annual cost of ~$110 for a 60W NAS and $220 for a 120W NAS.
I’m assuming you want Internet access to your NAS (perhaps to mirror its content off-site).I pay $110 / month for 100/40Mbps Internet with a static IP in Sydney.Obviously, I use that for more than just my NAS, but it means I’m paying $1,320 per year to ensure it is online.The static IP and upgrade to 40Mbps upload is $20 per month, so let’s say that’s the special “NAS” part of my Internet, which is $240 / year.
Finally, maintenance.Disks do fail, and you need to allow a budget to replace them (the cloud providers do).I’m going with 7.5% per year of the original purchase price, which should be enough to buy a replacement disk after a few years.That’s $90 / year for our $1200 NAS.
A quick comparison with AWS shows a NAS is similar in cost once you include ongoing costs:
- 4TB $1500 NAS costed over 5 years + electricity + Internet + maintenance: $300 + $110 + $240 + $90 = $740 / year.
- 2TB stored on AWS: $600 / year.
Reliability: Backblaze publishes best public statistics on HDD failure rates.
There’s a 1-2% chance of any hard disk failing each year (assuming data centre conditions; assume worse environmental conditions for your NAS).So it’s quite likely the disks in your NAS will survive 10 or more years.
On top of that, all NAS devices employ some kind of technology to detect and correct failures on a regular basis, and notify you when that failure happens.That means there is an automated system checking if your disks are working or not, so there should be a very short time between an actual failure and when you can take corrective action.
All this means, disks in a server are very, very reliable.Not quite as reliable as the cloud, but still very good.
Longevity: The NAS itself should last 5-10 years, at which point you’ll need to migrate data to a new device.
Disks should last forever, so long as you can afford timely replacements.That is, the automated monitoring built into NAS devices is really important at keeping your data safe.
The underlying technology of NAS is Ethernet + various file transfer protocols. While they may become obsolete in 10-20 years, I don’t see them disappearing entirely in that time frame.Every time you buy a new NAS (say every 10 years) you are automatically be upgrading this core tech.
Access: NAS devices support various file transfer protocols for Windows, Mac and Linux devices, so no problems accessing.Mobile device support is not as good, because mobile devices are “cloud first” platforms.
Access outside your local network is dependent on your Internet connection.While my residential connection might have a few minutes of down time each month (which I rarely notice), it’s no where near as good as cloud providers.
Scale: NAS devices support a fixed number of disks.Once you install all those disks, your choices are a) buy a new (bigger) NAS to scale up, b) buy a second NAS to scale out, c) get into clustered file systems - which are expensive and require IT experts.There’s only so many disks you can fit in a single server.
For personal and small business use, ~70TB is a reasonable upper limit for an 8 disk NAS with 12TB disks.Larger NAS devices are available supporting 16 disks (plus another 16 disk expansion), which gives ~320TB.
Scaling out and buying more NAS devices also works.But then you need to think of a way to split your storage up between each device.
Simplicity: Running your own hardware is always more complex than using “the cloud”; you need a higher degree of technical knowledge to get it right.Having said that, NAS devices are the easiest way to add reliable on-prem storage.Most consumer orientated devices will have wizards and walk-throughs to get you started.
And, if you’re a business that needs to store more than 50TB of data, you’ll likely have professional help available.
Automated: NAS devices run 24/7 and should be always accessible on your local network.Combined with a wide variety of storage protocols, pretty much any non-mobile device should be able to automate backups with your NAS.
That gets more complex if you need connections from outside your local network, depending on your Internet connection.
Security: Data is in your own hands, so the security and privacy of on-prem solutions are equally in your hands.All software listed have built in security and encryption - so the main point of failure is human: incorrect configuration or simply forgetting to revoke access to ex-employees.Also, make sure you keep your NAS up to date - bugs and security vulnerabilities are found frequently, updates are key.
Recommendations: NAS devices are a great way to store backups.They have good reliability and longevity, plus are competitive with the cloud on cost, and pretty easy to configure.If you need global access to your data, they might not be as good, depending on your Internet connection.
| Criteria | Rating |
|---|
| Capital Costs | 3/5 |
| Ongoing Costs | 4/5 |
| Reliability | 4/5 |
| Longevity | 4/5 |
| Access | 4/5 |
| Scale | 3/5 |
| Simplicity | 3/5 |
| Automation | 4/5 |
| Security | 4/5 |
| Overall Suitability for Backups | 5/5 |
| Overall Suitability for Archives | 3/5 |
On-Prem: External HDDs (offline disks)

Disks (either hard disks or solid state drives) can be purchased in an external enclosure with USB connection and stored in a safe place (possibly an actual safe).
In many ways, this is simpler than NAS devices.Buy a disk, copy data on it, stick it in a safe, done.
Capital Cost (AUD): $80ea (1TB), $100ea (2TB), $160ea (4TB).
You absolutely 100% must without exception buy multiple disks for redundancy.Data should be copied onto at least 2, preferably 3 disks.And then stored in different locations.
If you want to store them in a real safe you might need buy one. Costs start at $500 and can reach $3,000 for larger fire proof safes.
If you don’t care for a safe, storing disks on a bookshelf is nice and cheap (if not very fire resistent).
Ongoing Cost / GB (AUD): ~5c (2TB drive).
There’s no electricity being used, and no Internet required, so no ongoing costs for existing media.
OK, we should allow some maintenance because these disks will fail.However, we’ve already factored 2x or 3x redundancy in capital costs.
Cost per raw GB is 5c.You need to multiply that by your desired level of redundancy.
Reliability: While Backblaze publishes HDD failure rates, these do not apply to disks stored offline.
In my failure modes article, I looked for good statistics about the reliability and longevity of disks stored offline.There’s nothing remotely comparable to Backblazes’ data.
My anecdotal data: I used external disks for backups for ~5 years.The biggest source of failures was me dropping them accidentally.You can get rugged external disks which can mitigate this risk, but the “physical factor” is much more important when you’re physically moving disks around.
Longevity: As with reliability, there’s minimal data in this area.
Checking the table on my failure modes article, 5 years looks very safe, 10 years is possible, and 20 years is the upper limit.Solid state disks have a shorter life time (and we have even less data about them).
The advantages a NAS has in this area (automated reliability checks and notifications) doesn’t apply.You need to manually pull disks out of your safe on a regular basis, and test for correct operation.
USB should be around for another 10-20 years in some form, so that’s relatively safe.
Access: Offline devices are harder to access by definition.You need to manually retrieve the device, and connect it to a computer to read data.
An external catalogue of disk contents (or at least a good labelling system for the physical disks) is highly recommended.If you need to check every file on every disk, it might take a long time to find what you’re looking for.
Scale: Boxes of external disks scale up really easily: just keep buying more disks (and boxes).This assumes you can divide your data up logically (eg: by year or month).
Kinda interesting that a NAS has an upper limit because all the disks need to be running in the same device at once.While if you’re happy for your data to sit offline, the only limit to scale is your wallet and size of warehouse.
Simplicity: On one hand, “just copy data to disks and stick them in a safe” is about as simple as you can get. But retrieving that data can be extremely painful if you don’t have a catalogue or index of your disks.
Automated: By definition, offline / physical operations cannot be entirely automated.They can certainly be supported by scripts to copy data, reminders to move disks to the safe, and maintenance schedules.But any process that can’t be 100% automated can be forgotten, or done inconsistently.
The biggest risk is testing old disks.We have minimal data about how long we can leave a hard disk powered down and still be able to read data from it.So those tests are incredibly important.And also the most likely thing to be neglected or forgotten.
Security: Data is in your own hands, so the security and privacy of on-prem solutions are equally in your hands.Offline devices require physical access, which is much easier to understand - no key to the safe means no access.No hacker from the other side of the world can touch them.And (with the exception of when disks are attached to a computer) they cannot be wiped or encrypted by malware like Cryptolocker.
Recommendations: External disks are a reasonable offline storage mechanism.However, NAS devices are better for backups (because disk maintenance and backups can be 100% automated).And there are better options for long term archives (see below).
In spite of my negative recommendation, if the other options are unsuitable for your scenario, don’t make perfect the enemy of good.External disks are ∞% better than no disks at all.
| Criteria | Rating |
|---|
| Capital Costs | 4/5 |
| Ongoing Costs | 5/5 |
| Reliability | 3/5 |
| Longevity | 3/5 |
| Access | 4/5 |
| Scale | 4/5 |
| Simplicity | 5/5 |
| Automation | 3/5 |
| Security | 5/5 |
| Overall Suitability for Backups | 3/5 |
| Overall Suitability for Archives | 3/5 |

Writable CDs and DVDs are the most common forms of optical media.But I’m only going to consider Blu-ray disks here (because CDs and DVDs simply don’t have the capacity needed in 2021).Blu-ray capacity ranges from 25GB to 128GB.
The technological development of optical media has been left behind due to NAS devices and high speed Internet connections.But the Archival Disk is a Blu-ray successor designed explicitly for 50 year life time.(It also costs over $10,000 for drives, so out of reach for personal and small business scenarios).
Capital Cost (AUD): ~$200 for Blu-ray burner.
Assumption: you have a computer available to plug it into.Internal SATA and external USB burners are available.
As with external hard disks, you should buy multiple burners for redundancy.And you may need a safe, bookshelf or small warehouse for storage.
Ongoing Cost / GB (AUD): ~9c.
There’s no electricity being used, and no Internet required.
Single layer Blu-ray disks store 25GB and cost ~$2.15ea (on average).That works out to ~9c per GB.As with external hard disks, you need to factor your desired level of redundancy (minimum 2x, recommended 3x).
Note that I found Blu-ray media a little hard to find via Australian vendors.I resorted to e-Bay to import direct from the US or Japan with good results.
This is more expensive than external hard disks, but quite competitive with the cloud.
Reliability: Once burned and verified, I’ve found optical disks have very high reliability.Unfortunately, that’s based on my experience, not published data.
In my failure modes article, I outlined my anecdotal evidence for CD and DVD based backups still accessible after 10-20 years, even when there was no maintenance or regular tests done on the disks.This was a giant experiment that I didn’t realise I was running!But it shows a 99.9% success rate for optical media.
I’ve also done some “test to destruction” tests for Blu-ray disks: the real killer is direct sunlight.Every disk exposed to extended sunlight showed failures within 1 month.Heat and cold are less of a problem.
Scratches are a concern.Blu-ray has made improvements to disk coatings to mitigate scratches.But care when handling disks is still important.
Note that some Blu-ray drives support surface error scanning which can estimate if a disk is degrading and will fail soon.Apparently mine doesn’t (and ones that do are hard to come by).I found a reasonable proxy is the read speed: if a disk reads at high speed, it’s probably OK, if it reads very slowly and has a number of retries, it’s likely to fail soon.
Longevity: As with reliability, there’s minimal data in this area.
I consider optical disks a better way to store data offline, as compared to hard disks.Optical disks have separate reader and media: as long as your disks are OK, you can always buy another reader.Modern hard disks integrate the physical media and reading interface: so the data might be OK, but if the disk firmware or motor fails, its very expensive to read the data.
Blu-ray disks also use non-organic material.The organic dyes used with writable CDs and DVDs were a big concern (although I never observed failures).With Blu-rays, this isn’t an issue any more.Hard disks use a magnetic basis for storing data; this will decay over time if the drive isn’t powered on (although its unclear how quickly).
Finally, there is a Blu-ray M-disc technology which claims “a projected lifetime of several hundred years”.As far as I’m aware, there is no other consumer technology that makes such a claim.(And my test-to-destruction tests of M-disk Blu-rays has yet to cause a failure; 6 months and counting)!
As with external disks, you need to manually pull your Blu-rays out of your safe on a regular basis, and test for correct operation.
As long as you can purchase a new Blu-ray reader, you should be able to read data from the disks.Given that CD readers have been available for ~30 years and are still sold today, we’re reasonably safe here.
Access: Offline devices are harder to access by definition.You need to manually retrieve the device, and connect it to a computer to read data.
An external catalogue of disk contents (or at least a good labelling system for the physical disks) is highly recommended - and even more so for optical media as it is significantly slower than hard disks, and has lower capacity (so more disks).If you need to check every file on every disk, it might take a very long time to find what you’re looking for.
Scale: Boxes of Blu-ray disks scale up really easily: just keep buying more disks (and boxes).This assumes you can divide your data up logically (eg: by year or month).
Blu-ray disk capacity starts at 25GB for single layer disks.50GB duel layer, 100GB triple layer and 128GB quad layer disks are available.Be aware that the 100GB and 128GB disks use a slight different technique when burning, which makes them incompatible with older readers.
There are even disk library systems available (for $call) which store up to 50TB of data.
Simplicity: Optical disks are more difficult to write than external hard disks.Modern operating systems generally make this straight forward, but its more involved than “just copy data to disks”.Remember that retrieving data can be extremely painful if you don’t have a catalogue or index of your disks.
Automated: By definition, offline / physical operations cannot be entirely automated.They can certainly be supported by scripts to copy data, reminders to move disks to the safe, and maintenance schedules.But any process that can’t be 100% automated can be forgotten, or done inconsistently.
The biggest risk is testing old disks.Although I’m more confident about longevity of optical media as compared to external hard disks, we still don’t have much data on the topic.So those tests are incredibly important.And also the most likely thing to be neglected or forgotten.
Security: Data is in your own hands, so the security and privacy of on-prem solutions are equally in your hands.Offline devices require physical access, which is much easier to understand - no key to the safe means no access.No hacker from the other side of the world can touch them.And write-once optical media cannot ever be wiped or encrypted by malware like Cryptolocker.
Recommendations: Optical media is an excellent offline storage mechanism for TB scales of data.The best use case is for long term offline archives.NAS devices are better for short term backups (because they are easier to automate).
| Criteria | Rating |
|---|
| Capital Costs | 5/5 |
| Ongoing Costs | 5/5 |
| Reliability | 5/5 |
| Longevity | 5/5 |
| Access | 3/5 |
| Scale | 4/5 |
| Simplicity | 4/5 |
| Automation | 3/5 |
| Security | 5/5 |
| Overall Suitability for Backups | 3/5 |
| Overall Suitability for Archives | 5/5 |
On-Prem: Magnetic Tape

Magnetic tape has been around longer than hard disks, and is very well understood as a long term data storage medium.It’s capacities are significantly higher than optical media, and similar to external hard disks (1.5TB for LTO-5 tape).
While there are many standards for magnetic tape, Linear Tape-Open is the most common.
Note: my personal experience with tape is very limited (I used it for business client backups in ~2004).
Capital Cost (AUD): $1,500 to $7,000. And sometimes $call.
Lenovo, HP and Dell all sell new LTO-6, LTO-7 and LTO-8 tape drives.However, many don’t publish prices on the Internet.Finding the drives via other Australian vendors is also an exercise in futility.
These devices are available second-hand on eBay for $300-$2000.Although they are usually older (LTO-4, LTO-5, LTO-6).
Ongoing Cost / GB (AUD): ~1c.
There’s no electricity being used, and no Internet required.
Tape cartridges are slightly easier to find pricing for, and are available for $100-200ea.Interestingly, there isn’t a significant premium for newer cartridges; LTO-6, LTO-7 and LTO-8 are priced within $50 of each other.And when the capacity of those are 2.5TB, 6TB and 12TB respectively, the cost per GB is really good!
As with external hard disks, you need to factor your desired level of redundancy (minimum 2x, recommended 3x).
Reliability: As I’ve had no recent experience with tapes, it’s hard to know how reliable they are.
The reliability of magnetic data tape suggests it is very good.And given that tape (indeed any offline storage) is the last line of defence, high reliability is very important.
Given the low cost of tapes cartridges, it would seem very silly to only have one copy.The usual 2x or 3x redundant copies should apply to tape to ensure reliability.
Longevity: LTO tape is designed for 15-30 years of archival storage.
As with external disks, you need to manually pull your tapes out of your safe on a regular basis, and test for correct operation.
As an individual consumer, finding tape drives is quite difficult.I assume if I were a medium or large business, I’d have a direct line to a large vendor who would make this process very easy.And given that there are many LTO manufacturers, I’m assuming this is a relatively safe technology.
One thing I noticed was that a drive only supports the current tech, and previous 2.So an LTO-8 drive can read/write LTO-7 and LTO-8 media, and read LTO-6 media, but can’t touch LTO-5 and earlier.That’s not a great property.
Access: Offline devices are harder to access by definition.You need to manually retrieve the device, and connect it to a computer to read data.
An external catalogue of disk contents (or at least a good labelling system for the physical disks) is highly recommended - and even more so for tape media as it is significantly slower than hard disks.If you need to check every file on every tape, it might take a very long time to find what you’re looking for.
Scale: Boxes of tapes scale up really easily: just keep buying more disks (and boxes).This assumes you can divide your data up logically (eg: by year or month).There are even tape libraries that make it easy to work with many tapes (just don’t expect to be able to afford one in your home).
- LTO-4 capacity: 800GB
- LTO-5 capacity: 1.5TB
- LTO-6 capacity: 2.5TB
- LTO-7 capacity: 6.0TB
- LTO-8 capacity: 12TB
Simplicity: Tapes are even more complex and unusual than optical media.Because I haven’t had any recent experience with tapes, “not simple” is all I can say here.
Automated: By definition, offline / physical operations cannot be entirely automated.They can certainly be supported by scripts to copy data, reminders to move disks to the safe, and maintenance schedules.But any process that can’t be 100% automated can be forgotten, or done inconsistently.
Security: Data is in your own hands, so the security and privacy of on-prem solutions are equally in your hands.Offline devices require physical access, which is much easier to understand - no key to the safe means no access.No hacker from the other side of the world can touch them.There are write-once LTO tapes (although I understand that’s based on tape firmware rather than a physical proprty of the tape cartridge), and write-once media cannot ever be wiped or encrypted by malware like Cryptolocker.
Recommendations: Magnetic tape is an excellent offline storage mechanism for multi-TB scales of data.The best use case is for long term offline archives.NAS devices are better for short term backups (because they are easier to automate).
| Criteria | Rating |
|---|
| Capital Costs | 2/5 |
| Ongoing Costs | 5/5 |
| Reliability | 5/5 |
| Longevity | 5/5 |
| Access | 3/5 |
| Scale | 5/5 |
| Simplicity | 3/5 |
| Automation | 3/5 |
| Security | 5/5 |
| Overall Suitability for Backups | 4/5 |
| Overall Suitability for Archives | 5/5 |
Software
I’ll make brief mention of some useful software, when doing backups or archiving.
RClone
RClone is a command line app which can copy and synchronise data between many different cloud storage providers.In short, it can be used to mirror data from your NAS to AWS S3, or between AWS and Azure, etc.Its rather difficult to configure at first, but once working, its a fantastic way to ensure you have backups on both the cloud and an on-prem NAS.You do your backups to either the cloud OR your NAS, then use RClone to mirror to the other.
Cyberduck / mountainduck
Cyberduck, and its more powerful cousin Mountain Duck, are my go-to tool for GUI / interactive use of cloud storage.
Cyberduck is similar to an FTP client, letting you explore your data on most cloud providers via a powerful interface.
Mountain Duck lets you mount your cloud data as if it were a local disk drive.So you can explore work work with data using the same tools you use for disks or NAS data.
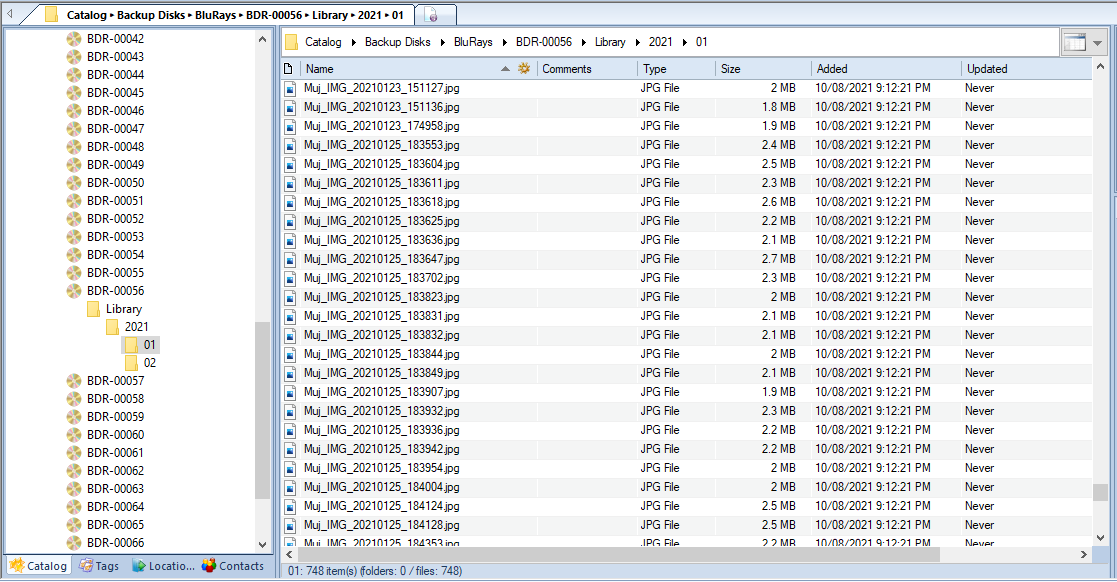
WinCatalog
Whenever I’ve discussed offline storage (hard disks, optical disks, tapes), I’ve recommended some kind of catalog or index, so you don’t need to inspect all your disks to find what you’re looking for.WinCatalog is such software.It’s interface feels a bit dated, but it is extremely effective at keeping a searchable catalogue of your external media.And that’s a huge improvement over “hmm… maybe what I’m looking for is on this disk… nope, let’s try the next one”.
This one is Windows only, and costs AUD $30 (although there are frequent discounts).
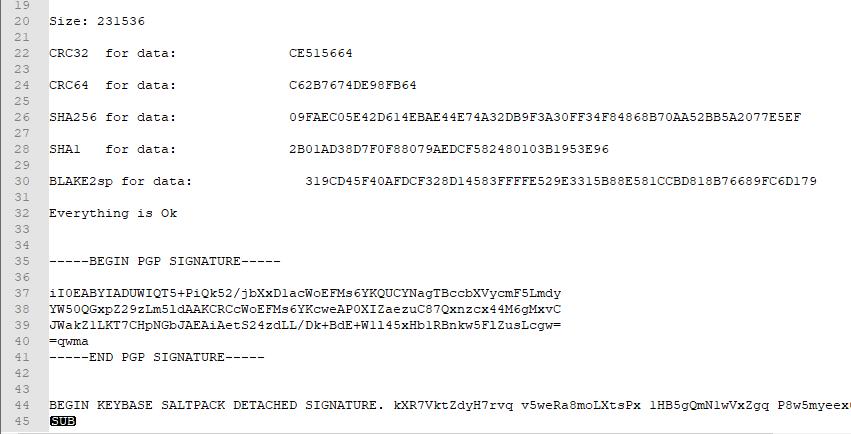
MultiPar
One risk when archiving data is the disk will only be partially readable, so certain files can’t be recovered.MultiPar lets you add redundant parity data to a disk to mitigate this risk.
While I use MultiPar to ensure the integrity of files (via hash / checksum), my primary way to mitigate partial disk failures is to make multiple redundant disks!External hard disks, optical media and tapes are relatively cheap - if you care about your data, just make 2 (or more) copies.
Conclusion
There’s lots of text, so here’s the TL;DR:
If you care about your data, you will have a copy on the cloud AND on-premises.
Cloud:
- The simplest backup solution is Cloud Sync. Excellent pricing, easy to use. Best for individuals.
- Cloud Object Store is best for business. Pricing is a pain, but otherwise there’s not much to dislike.
On-Prem:
- Network Attached Storage is the go-to for on-premises backups. And a great platform for a bridge between cloud and on-prem. Running costs make it less attractive for very long term archiving.
- Optical Storage (Blu-ray) is great for long term archives for individuals, small and medium business. Tape is for larger business.
Next up: I will outline my own choices of technology for personal and church backups (which you can probably guess based on my conclusions)!
Read the full series of Long Term Archiving posts.
]]>